Python (plankapy)
Thanks to hwelch-fle for the amazing work.
For more information, see the plankapy GitHub repository.
Installation
pip install plankapy
Documentation
The full documentation can be found here.
Getting Started
After pip installing, you can connect to a Planka instance using a Planka interface object
from plankapy.v2 import Planka
planka = Planka('https://planka.mydomain.com')
After creating the Planka instance, you can authenticate using the login method:
planka.login(username='username', password='password')
-- OR --
planka.login(api_key='MY_API_KEY')
Logging in for the first time required accepting the instance ToS. Consult with your instance admin on avalable ToS localizations and required ToS types for your user.
planka.login(username=..., password=..., accept_terms=True)
-- With Language --
planka.login(username=..., password=..., accept_terms=True, lang='ja-JP')
-- Specific ToS --
planka.login(username=..., password=..., accept_terms=True, terms_type='extended')
Now that you've authenticated with the server, you have access to everything that you'd be able to access through the web-ui
>>> planka.me
User({...})
>>> planka.projects
[Project({...}), Project({...}), ...]
Features
Fully Typed
Interfaces for all planka objects are fully documented and typed in the source, so if you are using an IDE that supports a python language server you will get full autocompletion.
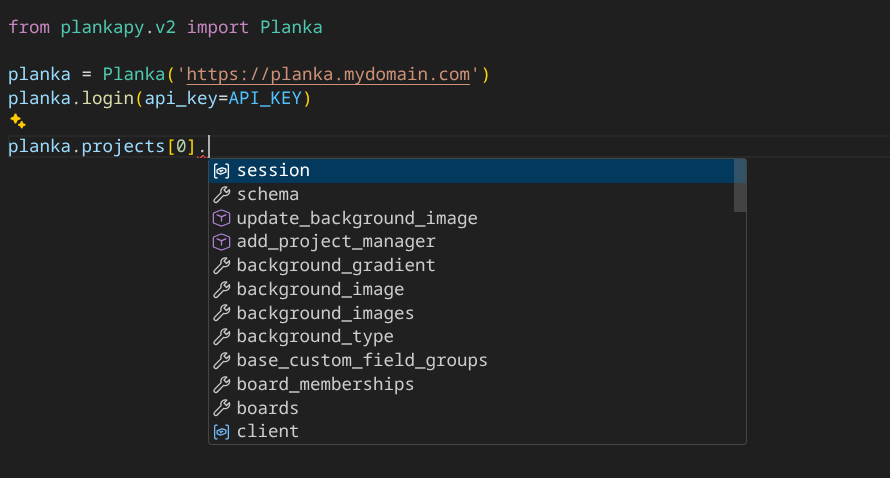
All methods are fully documented using doctrings and contain all info needed to properly form a function call:
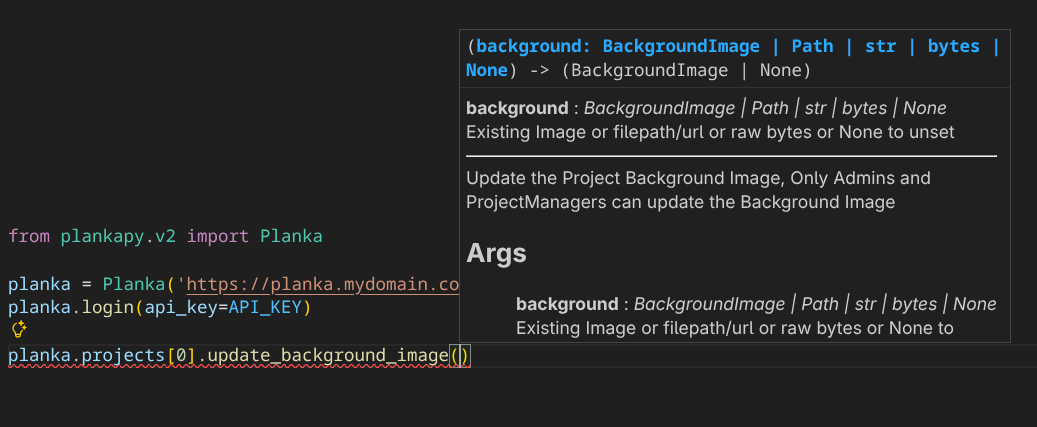
Since all objects are initialized as a series of endpoints with a local schema cache, it allows you to access any object from any other object in the tree without ever losing track of what you have:

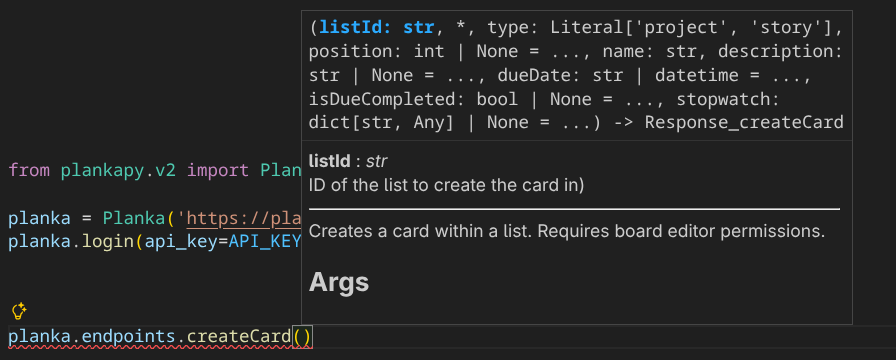
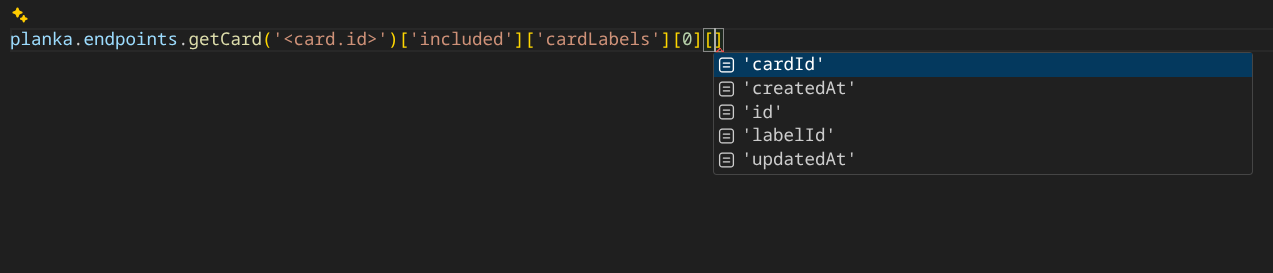
All endpoints and schemas are documeted using TypedDict syntax, so you can safely create raw API calls using the PlankaEndpoints object:
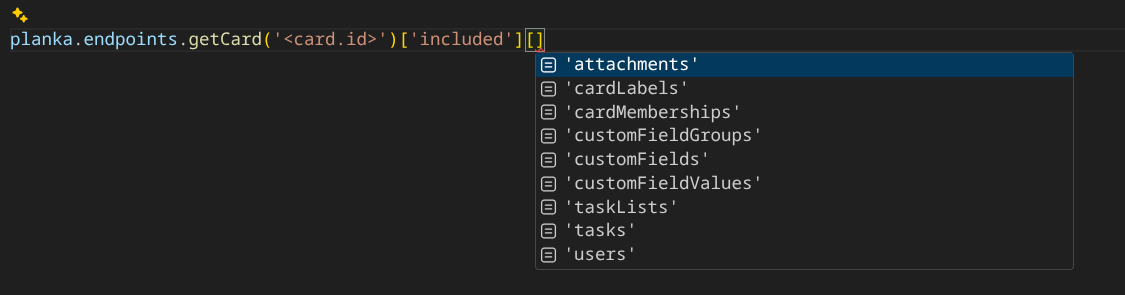
All responses are fully typed as well:

NOTE:
When using plankapy it is reccommended to turn your type checker settings to the strictest mode possible. Since most interfaces forego runtime checks for extensive type hints.
Model Lists
When reading the published docs, all property attributes that are typed as list[<PlankaModel[T]>] will be converted to ModelList at runtime. This list subclass can be used like a regulat list, bu allows indexing and filtering using __getitem__ syntax
int/slice
Since ModelList subclasses list, all regular list interfaces still work:
>>> board.cards[-1]
Card({...})
>>> board.cards[:2]
[Card({...}), Card({})]
str/Id
If a string is used to index a model list, the last model with the matching id is popped. If the id does not exist, the exception raised will be the same as popping from an empty list
>>> my_card_id = '...'
>>> board.cards[my_card_id]
Card({'id': '...'})
SchemaFilter/dict
If you want to define a filter on the model schema, you can pass a dictionary of schema values or expressions to the index:
>>> board.cards[{'name': 'My Card'}]
[Card({'name': 'My Card'})]
>>> board.cards[{'name': lambda name: 'My' in name}]
[Card({'name': 'My Card'}), Card({'name': 'My Other Card'})]
ModelFilter
You can also specify a raw expression to filter the list:
>>> board.cards[lambda card: planka.me in card.members]
Model
You can also direcly pass a Model to the index. The returned result is another ModelList that can be dpop'ed to check for membership
>>> board.users[planka.me].dpop()
None # Not in board
extract
Model lists also allow schema extraction using the extract method. If a single key is passed, a list of values is returned. If multiple keys are passed, a list of tuples of values is returned
>>> board.cards.extract('name')
['My Card', 'My Other Card']
>>> board.card.extract('name', 'dueDate')
[('My Card', None), ('My Other Card', '2026...')]
dpop
A way to safely pop from the model list. Has the same interface as list.pop but accepts a default keyword argument which is det to None when not set by the user:
>>> board.lists[0].pop(0)
IndexError...
>>> board.lists[0].dpop(0, 'Empty')
'Empty'
Live Updates
Every model contains a schema cache attribute that is used for direct attribute access. This means that checking the value of name for a card will not change until sync is called
>>> card = board.cards[{'name': 'My Card'}].dpop()
>>> card.name
'My Card'
# Change Name on server to 'Not My Card'
>>> card.name
'My Card'
>>> card.sync()
>>> card.name
'Not My Card'
If you want your functions to maintain sync with the server, you access the card via other endpoints. All properties that return item lists will re-construct themselves from the response when accessed
>>> card = lambda: board.cards[0]
>>> card().name
'My Card'
# Change Name on server to 'Not My Card'
>>> card().name
'Not My Card'
This example aliases a request chain to a callable lambda function. You can also just use the full desired request path too
>>> board.cards[0].name
'My Card'
# Change Name on server to 'Not My Card'
>>> board.cards[0].name
'Not My Card'
NOTE: This specific structure is written to always get the first card in the board. This could be useful, but you will usually want to apply a specific filter.
Attribute access in Loops
Since extended calls can fire off multiple requests to keep data synced, if you have a tight/hot loop that is accessing a lot of object attributes, it's best to explicitly use the schema cache:
>>> all_cards = ModelList()
>>> for project in planka.projects:
... for board in project.boards:
... all_cards.extend(board.cards)
>>> print(all_cards.extract('name'))
['My Card', ...]
Now you have an all_cards model list that contains the endpoints and a cache of all cards in your visible projects.
If you don't need the models at the end of the loop, you can instead just capture values:
>>> card_due_dates = []
>>> for project in planka.projects:
... for board in project.boards:
... card_due_dates.extend(board.cards.extract('name', 'dueDate'))
>>> print(card_due_dates)
[('My Card', '2026...'), ('Other Card', None), ...]
License
This project is licensed under the AGPLv3 License - see the LICENSE file for details.